


3D High-Fidelity Synthetic Data - DMS
Japanese OKWAVE Q&A platform Text Parsing and Processing Data

100 Hours - Burmese Speech Data by Mobile Phone_Reading
30 Million High-quality Video Data
80 Million Vector Image Data
200 Million High-quality Image Data

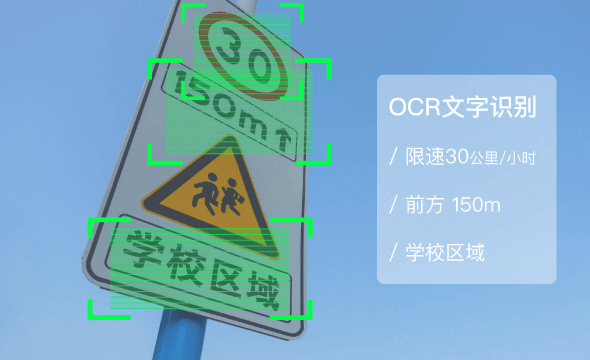
500,000 Images - Natural Scenes and Documents OCR Data
30,000 Images - Natural Scenes OCR Data in Southeast Asian Languages
100,000 Sets of ICONS Image Caption Data
6.9 million - Chinese Multi-disciplinary Questions Text Parsing And Processing Data
1 million - Chinese Code Questions Text Parsing And Processing Data
161 Hours - Gujarati Scripted Monologue speech dataset
32 million - Science Subjects Questions Text Parsing And Processing Data
114,000 - Chinese Contest Questions Text Parsing And Processing Data
2000 Hours - Spanish(Mexico) Real-world Casual Conversation and Monologue speech dataset
460 Hours - Swedish(Sweden) Real-world Casual Conversation and Monologue speech dataset
1,503 Hours - Arabic(UAE) Real-world Casual Conversation and Monologue speech dataset
1500 Hours - French(Canada) Real-world Casual Conversation and Monologue speech dataset
5,000 Images of Turkish Natural Scene OCR Data
155 Hours - French(Canada) Spontaneous Dialogue Smartphone speech dataset
. . .




 本社 〒101-0063
東京都千代田区神田淡路町2-105
ワテラスアネックス6階
本社 〒101-0063
東京都千代田区神田淡路町2-105
ワテラスアネックス6階 03-6256-8911
03-6256-8911 info@datatang.co.jp
info@datatang.co.jp
